Experiments that test for the effect of more than one treatment at once are more
efficient, compared with testing single treatments at a time. Experiments with more than one predictor are also
the only way that we can see how the effects of one treatment can be changed when combined with another.
Factorial designs look just like the randomized complete block designs we encountered earlier - every
combination of factor levels for the two treatments are used, with equal numbers of observations in each group.
With this design it is possible to assess the effects of each of the treatments independently, because their
effects are orthogonal to one another.
When we analyze a factorial experiment, we make a distinction between the main effects
of the predictors and interactions between them. Main effects are measured using marginal
means. Marginal means are simply the means for levels of just one of the treatments, ignoring the
levels of the other. Interactions are measured based on the subgroup means, which are means
for combinations of the treatment levels for both of the variables.
This distinction between main effects and interactions between variables is both one of the most
powerful aspects of linear modeling, and one of the most easily misunderstood. A statistical interaction means
that the effect one predictor has on the response depends on the level of the other predictor.
We would use models with interactions to test for biological effects such as:
Synergy - the effect of one treatment on a response variable is enhanced by another. For example,
consumption of either alcohol or tobacco alone increase risk of esophageal cancer by 25%, but consumption of
both increases risk by 300% (not 50%, like we would expect if the effects of alcohol and tobacco were
independent)
Inhibition - the effect of one treatment is dampened or eliminated by another. For example, low doses of
aspirin are often taken to prevent blood clots that cause heart attacks and strokes. Taking ibuprofen at the
same time interferes with aspirin's anticoagulant effects, and blocks the positive effects of aspirin.
Multifactorial control - more than one
factor may be needed to produce a response. For example, providing food alone to your pets will allow them
to survive for several days, providing them water alone will allow them to survive for several days, but
providing them both food and water is needed to keep them alive indefinitely.
Possible outcomes - main effects and interactions
To get an idea of what an interaction is testing for, consider the example from your book of an experiment on
the amount of fat eaten by male or female rats. The fat fed to the rats was either fresh or rancid. Each
combination of fat type (fresh, rancid) and sex of rat (male, female) was tested, with equal numbers of rats in
each combination - that is, the design was complete and balanced.
Main effect of sex:
Main effect of fat type:
Interaction between sex and fat type:
ANOVA table
The graph on the right is an interaction plot, in which one of the predictor
variables (sex) is on the x-axis, and the other predictor represented by separate lines (fat type). There are
additional symbols on the graph that are not usually included in an interaction plot, but they are there to
indicate the locations of marginal means for each sex (pink dot for the female marginal mean, baby blue dot for
the male marginal mean - cheesy, I know, but it will help you remember what they are), and each fat type (the
stars in the middle of the lines for each fat type). The symbols showing marginal means are used to calculate
main effects - if the pink and blue dots are not at the same location along the y-axis there may be a main
effect of sex, and if the stars are not at the same location along the y-axis there may be a main effect of fat
type. The effects are expressed as differences between the relevant means - for example, the Main effect of sex
of 35.5 says that the difference between the male and female marginal mean is 35.5 g.
Initially the graph shows the actual data. Before we change anything, let's interpret the actual
observed results.
The plot shows lower levels of rancid fat eaten than fresh fat for both of the sexes, and the marginal mean
for rancid (red star) is lower than for fresh (blue star). Since the marginal means appear to be different we
would expect there to be a significant main effect of fat type in the ANOVA table below the graph, and there
is. Main effects are reported in an ANOVA table using the name of the variable by itself, so look at the row
labeled "Fat".
The average amount of fat consumed for females is not identical to the amount consumed for males, but the
marginal means (pink and baby blue dots) are close together. The observed difference is not enough to be
statistically significant, so the main effect of sex is not significant in the ANOVA table (look at the row
labeled "Sex").
The lines are not perfectly parallel, but they are nearly so because the difference in the amount of fresh
and rancid fat eaten is nearly the same for females and for males. When the lines are parallel this means that
the difference in amount eaten for rancid and fresh fat is the same for both sexes, and thus the difference is
independent of sex. We wouldn't expect a significant interaction, and if you look at the row in the table
labeled Sex x Fat you'll see it is not.
Now that you're oriented, let's start making some changes.
First, set all of the differences to 0. This will make the means all exactly the same, and the lines will be
at the grand mean fat consumed (which is 597.75 g).
Try introducing a main effect for sex, while keeping the other terms at 0 - enter 200, which represents 200g
difference in the marginal means between the sexes. You'll see that the lines stay on top of each other, but
they tilt because the means for each sex are different. If you hover over the pink and baby blue dots you'll
see that the female marginal mean is 497.75, and the male marginal mean is 697.75, for a difference of 200 g.
Set the sex difference back to 0, and set the difference between fat types to 200. The lines now separate,
and the stars are 200g apart. Since the sexes don't differ the pink and baby blue dots are now the same (at
597.75), and since there is no interaction the lines are parallel because the means for males and females are
the same within each of the fat types.
Set the fat type difference back to 0, and set the interaction effect to 200. The lines are no longer
parallel, because now females eat more rancid fat while males eat more fresh fat. With only an interaction and
no main effects, the lines cross in the middle and are perfectly symmetrical. This places the marginal mean
for males and females at the same place (thus no sex main effect), and the marginal means for fresh and rancid
fat at the same place (thus no fat main effect). From this graph you should see that:
It is possible to have an interaction without significant main effects.
The lack of main effects doesn't mean that sex or fat type don't matter - there is a difference in amount
of fat consumed between the fat types, and the direction of the difference depends on sex, so neither of
these predictors is without effect on the outcome. If there is a significant interaction between two
variables then both are having an effect, whether their main effects are significant or not.
With the interaction kept at 200, make the sex effect 200 as well. Now the lines are tilted, but the
interaction causes them to cross. From this graph you should see that:
The main effect of sex is significant, because the pink and baby blue dots are at different locations. The
main effect suggests that females eat less fat than males.
However, the interaction is due to the fact that the lines cross. The amount of rancid fat eaten is
actually exactly the same for the two sexes, and it is only the fresh fat that is different between them.
The interpretation of the main effect would not be accurate if we were only feeding rats rancid fat. The
main effect can be misleading in the presence of an interaction.
Set the sex effect to 0, keep the interaction at 200, and set the fat effect to 200. From this graph you
should see that:
Means for the fat type lines are now different, so there is a main effect of fat type
The amount of difference between the lines is 0 for females but 400g for males - the consumption of fresh
or rancid fat depends on sex, so there is an interaction. The main effect of fat tells us that more fresh
fat is eaten than rancid fat, but this is only true for males. Again, the interpretation of the main effect
can be misleading in the presence of an interaction.
Now, lastly, set every effect to 100. Notice that:
The marginal means for sex are different (pink and baby blue dots), so the main effect of sex is
significant - males eat more fat on average than females.
The marginal means for fat type are different (stars), so the main effect of fat is significant. Rats eat
more fresh fat than rancid.
The amount of difference between the fat types is different for males and females. Males only eat more
fresh fat than females, but the amount of rancid fat they eat is the same. The main effects say that more
fresh fat is eaten and that males eat more than females, but neither of these statements is true in all
cases. Once again, main effects can be misleading in the presence of an interaction.
Feel free to play around with the numbers until you're able to tell by looking at the graph whether the main
effects and interaction will be significant. Bear in mind that actual interaction plots will not include dots
for the marginal mean, so use them as a learning tool, but realize that you'll need to make educated guesses
about where the means will be for each of the levels of the first predictor along the x-axis, and across each of
the lines representing the different levels of the second predictor when you're interpreting interaction plots
(of course, the final word on whether effects are significant will be the p-values in the ANOVA table, but
learning to read the graphs will help you understand the statistical results).
Since the observed results only show a significant effect of fat type the interpretation is very simple - the
marginal means of rancid and fresh fat differ. But, since we now know that significant interactions complicate
interpretation, we will need to wait for an example with a significant interaction to learn how to proceed. This
will be the subject of this week's activity.
Instructions
Today you will conduct an analysis on some contrived data from a plant growth experiment. You are probably well
aware that plants need sunlight and water to grow. Providing a plant with just one of these two requirements is
not sufficient to keep it alive. Given this, if we were to conduct an experiment in which we varied water and
sunlight as two predictor variables, the amount of growth we will get in the plants should be much greater when
both sunlight and water are provided.
Our two predictors then are:
Water - levels are none, adequate
Light - levels are none, indirect, and direct
The response variable will be the height of the plants.
Start a new project in R Studio for this exercise. The Rmd file for you need is here,
and the data you will use are in this file.
Import the data from interaction_examples.xls into a data set called "plant". If you view the data set, you'll
see a column for the dependent variable (height), and one each for water and light. Every combination of light
level and water level is present, with an equal number of replicates (3) used for each combination - thus, the
experiment is complete and balanced, which makes the predictors orthogonal to one another.
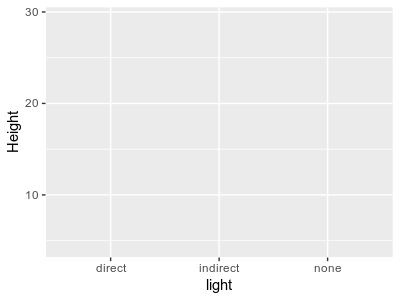
1. Before you run the analysis, predict what the results will be. On the blank axes to the left, draw in the
results you would expect from this experiment:
Draw a line for each water level, Adequate and None (use the correct color for each). Lines on an interaction
plot connect means that are all in one predictor level - in this case the lines connect all three group means
that were in the same water level. To help you think through where the line should go, put a dot where you
expect the means would be for each light level given the water level you are drawing. The easy water level is
None - it should be obvious that when you don't water plants they don't grow, regardless of the light level, so
the locations of the means should be easy to anticipate for the None water level. Once the dots are in place,
connect them with a line. Switch to the Adequate color and do the same there (you may not know whether Direct or
Indirect light will be better, but you can probably anticipate how well the plants will grow with no light, even
if you water them - put the dots for Adequate water someplace above the three Light treatment levels that makes
sense to you and connect them with a line).
With the red pen (labeled Light marginal) draw a plus (+) for the location of the marginal mean for each light
level - they will be in between the two means at each water level. These are the basis for measuring the main
effect of light, and if they are not all at the same Height you can expect a main effect of light.
With the black pen (labeled Water marginal) draw an x for the location of the marginal mean for each water
level - you would average all the means for Adequate water (the pink line) to get the Adequate marginal mean,
and all the means for water level None (teal line) to get the marginal mean for None. If these two marginal
means are not the same then you can expect a main effect of water level.
What of an interaction? If the lines cross, converge, or diverge as you move from the left to the right side of
the graph that indicates that the amount of difference between the water levels depends on the light level, and
you should expect an interaction between light and water.
Once you are done, click the "Download" button - the file you download should be called "graph.png",
place it in your project folder (you should see it in your Files tab). Your Rmd file will add your drawing to your
knitted output file automatically as long as it is in the same project folder as the Rmd file, and is named
graph.png.
Now, on to the data analysis.
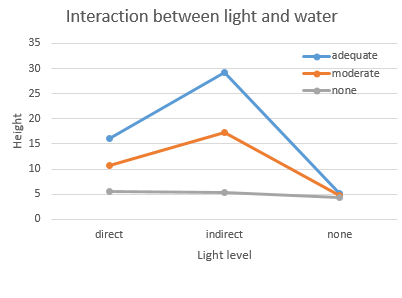
2. First, you should look at your data. We will use ggplot2 to make an interaction plot that
uses two different grouping variables and a numeric response. This interaction plot will look much like the
hand-drawn graph you just made - it will have means for each possible combination of light and water level, color
coded by water level and with lines connecting means for a water level across the three light levels.
We will need means and standard errors, so use summarySE to get those, and assign them to an object called
plant.sumstats (in your Rmd file, summarize.plant.data chunk - don't forget you need to load the
Rmisc library to get the function):
water light N
height sd
se ci
1 adequate direct 3 16.10000 2.847806 1.644182 7.074343
2 adequate indirect 3 29.26667 3.847510 2.221361 9.557745
3 adequate none 3 5.20000 1.352775 0.781025 3.360479
4 none direct 3 5.50000 1.873499 1.081665 4.654031
5 none indirect 3 5.40000 2.163331 1.249000 5.374012
6 none none 3 4.40000 2.971532 1.715615 7.381694
The two grouping variables you provided are the first two columns of plant.sumstats, and you can see that each
row is a different combination of water and light.
Now you can graph the means for each combination of light (on the x-axis) and water (grouped and color-coded),
with lines connecting the means from the same water level (Rmd file, graph.plant.data chunk):
ggplot(plant.sumstats, aes(x = light, y = height, color = water, group = water)) +
We have been writing ggplot() commands all strung together in a line, but it works to hit a carriage return after
each + so that the command is easier to read.
Based on the graph you should have some idea of what is going to happen when you fit the model - the lines are
clearly not parallel, so we have reason to expect an interaction.
3. Fit the model. The complete model specification for a GLM with an interaction would be:
height ~ light + water + light*water
Main effects are indicated by the names of the predictors added together, and interactions are indicated as one
predictor multiplied by another - this is literally how the interaction is represented in the GLM, as dummy-coded
columns multiplied together (when both predictors are categorical), as a numeric column multiplied by dummy-coded
columns (if one is categorical and the other is numeric), and as two numeric columns multiplied together (if both
predictors are numeric). The asterisk indicates multiplication in R (and in most programming languages).
But, linear models are hierarchical, meaning that you can't include an interaction term without also including
main effects for each of the factors. Because of this, to shorten and simplify the model specification R allows us
to use just the highest-order interaction to specify the model - thus, all you need is (Rmd file,
fit.lm chunk):
lm(height ~ light*water, data = plant) -> plant.lm
Including the light*water interaction in the model requires that main effects are also included, so it isn't
necessary to write them in.
This model is balanced and complete, meaning that there are equal numbers of data points in each combination of
light and water, and every combination is included in the data set. Because of this, light and water are
orthogonal, and it won't matter if you use Type I or Type II sums of squares. You can confirm this is true by
getting both a Type I SS ANOVA table (from anova()) and a Type II SS ANOVA table (from Anova(), in the car
library). Get each and confirm that they give the same results (you can put these commands in the fit.lm chunk
below your lm() command).
4. We definitely have a statistically significant interaction between light and water, so now what?
The significant interaction means that we can't interpret the main effects as some sort of general pattern - for
example, if we just did Tukey post-hocs on light level, we would get a significant increase in height for indirect
light compared to the other two light levels, but this would entirely be due to the high mean obtained when
adequate water is provided - if you don't water the plants you don't get this positive effect of indirect light.
Given that we are going to have to explain this contingent relationship between water and light, the main effects
don't really add anything to our understanding of the biology of the system. To understand what's going on, we
need to compare pairs of means for combinations of light and water.
But, which comparisons to make depends on what we really want to know. Our choice of post-hoc analysis will
depending on the question we're interested in answering:
Question 1: what is the best combination of light and water?
Our graph shows that the combination of adequate water and indirect light gives us the tallest plants, but this
combination may not be statistically significantly different from all of the other means. We can find this out by
comparing the means for all of the combinations, using Tukey tests.
The simplest method of comparing all the combinations of factor levels to one another in R is to use emmeans()
with tukey ~ light*water to define the comparisons to be made - this argument will compare heights for every
combination of light and water. In the tukey.light.water chunk of the Rmd file enter:
P value adjustment: tukey method for comparing a family of 6 estimates
You can see that each row of the Tukey tests table is comparing one combination of light and water to another,
and every combination is compared against every other. You can get a compact letter display by using the cld()
function in the multcomp library - in the same code chunk, enter:
multcomp::cld(plant.emm)
and you will see that the following is added below the Tukey comparisons:
Confidence level used: 0.95
P value adjustment: tukey method for comparing a family of 6 estimates
significance level used: alpha = 0.05
NOTE: Compact letter displays can be misleading
because they show NON-findings rather than findings.
Consider using 'pairs()', 'pwpp()', or 'pwpm()' instead.
You'll see the groups identified in the .group column. You can also see that the authors of emmeans disagree with
the authors of multcomp about the wisdom of using compact letter displays!
This approach of comparing every combination of light and water is the most information rich, because every pair
of means is tested. The problem is that with 2 water levels and 3 light levels there are six different
combinations, and it takes 15 different comparisons (with 15 p-values) to test all of the means against each
other. This is an issue because the p-value is adjusted for the number of comparisons, and comparing all of the
means against one another reduces the power of each comparison. If you really want to compare all of the
combinations, this is unavoidable, but it may be that you can answer all the questions you care about without
doing all of these comparisons.
For example, if your question is...
Question 2: at each level of water, which light levels are different?
then you can reduce the number of comparisons that you make by more than half. If we only make comparisons
between the three light levels that have adequate water, and the three light levels that have no water, we only
have to test a total of six differences. Using this approach sacrifices comparisons between water levels, so we
can't talk about the differences between water levels when we present our results, but if we already know that
watering plants is important and are only interested in how water level and light level interact, then this may be
a good choice. Fortunately, emmeans() provides a very simple way to do these comparisons (Rmd file,
light.given.water.level chunk):
emmeans(plant.lm, tukey ~ light | water)
You'll see in the output window that you get lines that look like this:
$emmeans
water = adequate:
light emmean SE df lower.CL upper.CL
direct 16.1 1.52 12 12.78 19.42
indirect 29.3 1.52 12 25.95 32.59
none 5.2 1.52 12
1.88 8.52
water = none:
light emmean SE df lower.CL upper.CL
direct 5.5 1.52 12 2.18 8.82
indirect 5.4 1.52 12 2.08 8.72
none 4.4 1.52 12
1.08 7.72
Confidence level used: 0.95
$contrasts
water = adequate:
contrast estimate SE df t.ratio p.value
direct - indirect -13.2 2.15 12 -6.112 0.0001
direct - none 10.9 2.15 12 5.060 0.0008
indirect - none 24.1 2.15 12 11.172 <.0001
water = none:
contrast estimate SE df t.ratio p.value
direct - indirect 0.1 2.15 12 0.046 0.9988
direct - none 1.1 2.15 12 0.511
0.8676
indirect - none 1.0 2.15 12 0.464 0.8891
P value adjustment: tukey method for comparing a family of 3 estimates
The output is divided into a set of comparisons for adequate water and another for no water, which makes it
appear that the data are being split and analyzed separately, but this is not the case - the fact that the same
standard error is being used for each comparison makes it clear that Tukey comparisons are being used, and is
adjusting for all six of the comparisons.
The command is smart enough to work with either variable set as the conditional variable - try it using light as
the conditional and water as the test variable and see what happens (Rmd file,
water.given.light.level chunk).
Interactions vs. correlated predictors
There's a question in your Rmd file about the difference between interactions and correlated predictors - before
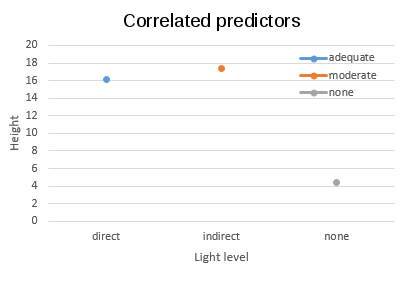
you try to answer it read through this explanation of the issue. It's easier to see the point if we have an equal
number of levels in the light and water data set, so the graphs show three levels of water - I added a "moderate"
level, which is just halfway between the adequate and none water levels at each light level.
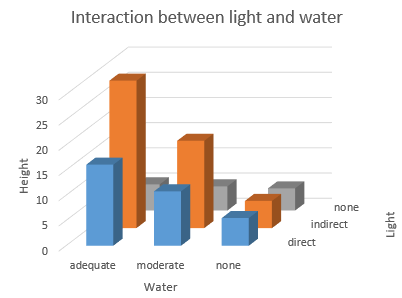
We set up a factorial design using all possible combinations of light level and water level, with equal
numbers of replicates in each cell (i.e. each combination of light and water). The graphs to the left show
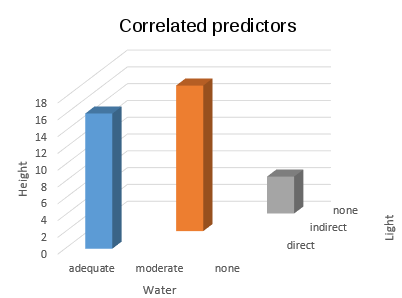
the patterns of response in both a (now familiar) interaction plot, and as a three-dimensional bar chart.
The interaction plot shows the lack of parallel in responses (i.e. heights) for the combinations of the
predictors, but the 3D plot shows the design of the experiment better - you can see that all the
combinations of light and water were used (it is complete), and assuming the sample size is the same for
all of the cells we can measure the effect of water independently of our measurement of the effect of
light - the design is orthogonal.
Because we have an orthogonal design, we can see that the response to one predictor (e.g.
light) depends on the level of the other (e.g. water) - if no light is provided then the effect of water
is essentially zero, but if either direct or indirect light is used then the plants grow better with more
water, the effect being greatest for indirect light.
But, what if instead of a nice balanced, complete design we had used only the combinations
direct.adequate, indirect.moderate, and none.none? You can see on the 3D plot that this introduces a
correlation between the predictors that is so severe that the predictors are completely confounded - each
water level is matched with just one light level, so it's impossible to tell if the response is due to
water alone, light alone, or an interaction between the two.
So, correlated predictors are a design-level problem that makes it difficult to tell how each predictor affects
the response variable. Interactions measure the extent to which response to one variable depends on another, and
we can't even assess whether interactions exist unless we have enough independent variation between the predictors
to measure their joint effects.