Estimation, sampling distributions, and confidence intervals.
 Today
you will be estimating means of a population, using samples of different
sizes. To help us understand what confidence intervals tell us, and how
they behave at different sample sizes, we will simulate the process of
estimating the population mean for birth weights of babies.
Today
you will be estimating means of a population, using samples of different
sizes. To help us understand what confidence intervals tell us, and how
they behave at different sample sizes, we will simulate the process of
estimating the population mean for birth weights of babies.
First, we will work with some simulated data on birth weights of babies from modern times. We will focus in this part of the exercise on understanding how confidence intervals work - what we can and cannot know about the population mean based on a sample estimate, and how what we can know is affected by the amount of data we collect.
Second, we will apply what we learn about estimating means from a sample to answer a question about how birth weights have changed over time.
Part 1 - understanding the effects of sample size on confidence intervals
In the real world, if we were trying to estimate the birth weight of babies, we would collect a random sample of babies born in a year, measure their birth weights, and then calculate a mean of the sample. This would give us a single estimate of the unknown population mean. We can be pretty sure because of random sampling that the sample mean will be at least a little different from the population mean, and that our estimate is therefore wrong by some unknown amount. If we don't know the population mean we can't measure how far off we are, but what we can do is to can calculate a 95% confidence interval. The confidence interval tells us the range of possible values for the population mean that have a 95% chance of being correct, given the amount of variability we expect in our sampling. We would like our sample mean to be as close as possible to the population mean we are estimating, and thus we would like it if our 95% confidence interval is as small as possible, because that would indicate that our estimate has a good chance of being close to the actual population mean.
Enter a sample size:
It's helpful when you are learning how sampling and estimation works to start with a case in which you actually know the value you are trying to estimate, so you can measure how well your sampling is working.
One way of knowing the correct value is to use a simulation, in which we set up a population with a known mean and standard deviation and then randomly sample from it, which is what is being done in this graph. The mean birth weight for babies in the US is 3,398 g (excluding twins, which are generally smaller), with a standard deviation of 466 g, so these are the population values used for the simulation.
The simulation works as follows: 100 different samples of 10 babies (initially) are selected, a mean is calculated as an estimate of the population mean for each sample (the dots in the middle), and a confidence interval is constructed around each estimate (the error bars around the means). Each time you hit the "Sample 100 more" button another set of 100 random samples is collected. By selecting a large number of samples we can see how the process of estimating a population mean from a sample mean works in general, as well as how badly we can possibly go wrong in individual cases.
Since we know the true population birth weight for this simulation is 3,389 g, we can check whether each confidence interval contains the population mean - the blue horizontal line is at 3,389, and the confidence intervals that don't cross this line (and thus do not contain the population mean) are shown in red. With 95% intervals we would expect 5% of the intervals to miss the population parameter, so...how many should be red? Click here to see if you're right.
Now that you understand how it works, you will use the simulation to see how a large number of random samples behave, at four different sample sizes (5, 10, 50, and 100).
1. We will start with the sample size of 10, which is already entered by default. Count up how many (red) confidence intervals don't include the population mean and record that number in the the first table of your worksheet, in the row for n of 10, in the column labeled 1.
Then, hit "Sample 100 more" and record the number of intervals that don't include the population mean in the column labeled 2. Repeat for columns 3 through 10
Total up the number of intervals that did not contain the population mean and enter the total in the final column.
2. Lower the sample size to 5 and repeat the procedure. If the intervals get too large to see on the graph you can use move the graph up and down along the y-axis by dragging, and can zoom in and out with the scroll wheel (clicking with the right mouse button resets to the default graph settings).
3. Do one more set of intervals at each sample size, but this time pay close attention to two things: a) how big the confidence intervals are, and b) how far from the true population mean the estimates of the mean fall. What you should see is that with bigger sample sizes the confidence intervals get narrower, and the sample means stay closer to the true value.
You can answer questions 1 through 6 based on this part of the exercise.
Comparison of 19th century data to modern data
Now that we understand how confidence intervals work, we can think about implications for what we can know about birth weights from a sample of data.
We have some real data on birth weights collected during the years 1848 through 1873 at an almshouse in Pennsylvania (almshouses were like homeless shelters, and poor women often had to deliver their babies at them), and it would be interesting to compare the data to modern birth weights to see if they have changed over time. There are a couple of different reasons that birth weight might be different - first, there may have been a change in human populations in general that is reflected in the data from this almshouse, or second, it could be that lack of prenatal care and difficult living conditions for poor people during the mid-19th century could have led to low birth weights. Since women giving birth in almshouses were among the poorest of the poor, it would not be surprising if their babies were low birth weight.
The question we will address next is, how can we tell if the birth weights from this almshouse are the same as modern birth weights or not? We will again simulate the process of sampling data from a population, but this time we will use the almshouse data as the population (there are 4,598 records in the data set for us to sample from). We know now that random sampling is unbiased, even at a small sample size, so can we learn what we need to know from a sample of 5 babies from this data set? Or do we need a larger sample size? If it needs to be larger, how much larger?
We will address these questions by having each student draw random samples from the almshouse population at each sample size, and then compare their estimates and confidence intervals to modern birth weights. To help make the point about the need for adequate sample sizes, we'll compare the estimates and intervals to the modern singleton birth weight (3,389) as well as to the modern twin birth weight (2,564). Twins are usually substantially smaller than single births, even with adequate nutrition and prenatal care. If a confidence interval is so wide that it overlaps both of these very different numbers then either one could be the population mean for the almshouse samples, and we don't have good enough precision to draw a conclusion.1. Download and open this file. Make sure that the window for this worksheet is on top of all the others.
2. Random sampling can be done by issuing commands in the "Session" window. Click the "Session" window to activate it, and then select from the menu bar "Editor" → "Show command line" (this option only appears in the menu bar if the Session Window is active). This will place a "command prompt" within the session window, at which you can type commands. The prompt looks like this:
MTB >
3. For your first sample, you will be randomly selecting birth weights of five babies from the "Birth weight" column, and placing them in the "n5" column. To do this, type the following (type everything EXCEPT the "MTB >" part):
MTB > sample 5 'Birth weight' 'n5'
NOTE: Although the completed commands will still be visible in the session window, you cannot simply edit them in place and re-issue them. You can, however, copy and paste a command to the bottom-most MTB> prompt, and edit it as needed before hitting enter.
Repeat this procedure for the other three sample sizes (10, 50, 100).
Remember both to change the sample size, and to make the column name
match the sample size each time (so, for example, to sample 10 babies
change the command to: sample 10 'Birth weight' 'n10').
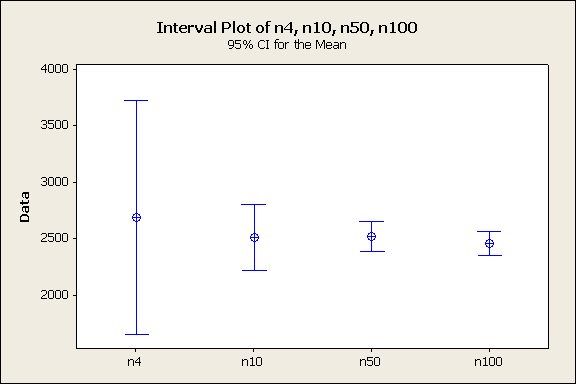
4. Once you have a sample at all four sample sizes, construct an "interval plot". Select "Graph" → "Interval plot", then use the "Multiple Y's", "Simple" option. Each column in your worksheet is a different variable as far as MINITAB is concerned, so a graph that uses one column of numeric data is a "Single Y" graph, and one that uses several numeric columns is a "Multiple Y" graph. Add all of the sample columns (n5, n10, n50, n100), and click "OK". The plot should look roughly like this, and will display 95% confidence intervals by default. Bear in mind that every student will get a different sample of babies, so no two students will have identical graphs, and none will look exactly like my examples; what will be the same is that everyone should have one mean and confidence interval for every sample size. Include this plot with your assignment sheet.
{kind=link}
{kind=link}
{kind=link}
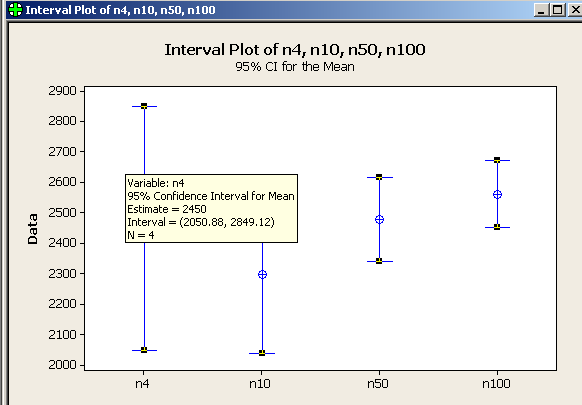
If you click on one of the error bars in the graph the set of four means and error bars will be selected. If you now hover over each of the bars with your mouse a yellow box will pop up that looks like this, and gives the name of the variable, the mean (called the "Estimate"), and the lower and upper ends of the confidence interval in parentheses (Interval = ...). Record the mean (estimate), lower, and upper interval on your worksheet.
{kind=link}
**Report the lower and upper limits in the class database. I will produce a graph of the class data that you can use to finish answering the questions on your worksheet.
5. We are sampling from the 19th century data set to learn about sampling, but of course if we really want to know what the 19th century almshouse data mean is we should use all of the data, not a small sample of it. Use MINITAB's "Display descriptive statistics" menu to calculate the mean and standard error for the entire set of 4,598 records, and report them to your worksheet. Then look up the t-value needed to calculate a confidence interval from to this t-table (use the column with with an α(2) of 0.05 - the α refers to the proportion of possible means that won't be included in the interval, and the 2 refers to the fact that we're excluding them evenly on 2 sides, above the upper limit and below the lower limit). You would need a t-value for 4,598 - 1 = 4,597 degrees of freedom, which you'll see does not appear in the table, but since the t-values are identical to two decimal places above df of 1000 you can use 1.96 as the t-value.
Calculate the confidence interval for the sample mean, and then check if the modern singleton birth weight falls inside of the interval - if so, then the modern mean has a good chance of being the population mean for the 19th century data as well, and we have no reason to think birth weights have changed. If the modern mean is not inside of the interval it's unlikely to be the population mean for the 19th century data, and we then have reason to think that the 19th century birth weights were different from today.
Challenge questions
Part I - Cheryl is a toxicologist from the Environmental Protection Agency (EPA) who is charged with testing whether mercury concentrations in tuna are above the level considered safe for human consumption. Average mercury concentrations in a catch of tuna above 1 part per million (ppm) are considered unsafe, and when the average concentration for a catch cannot be shown with 95% confidence to be below this level the entire catch has to be discarded. Cheryl samples 32 individual tuna for mercury content from a large catch, and the data are in the first two columns of this worksheet; column C1 (Tuna number Sample 1) indicates which of the 32 tuna the sample was taken from, and column C2 (Mercury concentration Sample 1) gives the concentration in ppm.
a. To three decimal places, give the mean, standard deviation, and standard error of the mean:
b. Calculate the 95% confidence interval for the mean mercury concentration.
c. Should Cheryl allow this catch of tuna to be consumed, based on these findings? How do you know?
Part II. Cheryl was concerned about the result of her first calculation, and decided to collect more data. She collected a new, larger sample of tuna, and the results are in columns C5 (Tuna number Sample 2) and C6 (Mercury concentration Sample 2).
a. To three decimal places, give the mean, standard deviation, and standard error of the mean.
b. Calculate the confidence interval for the mean mercury concentration in this second, larger sample.
c. Should Cheryl allow this catch of tuna to be consumed? How do you know?
d. Why did Cheryl collect a bigger sample? Why might a larger sample have led to a different conclusion?
e. With an upper limit for the confidence interval that falls below 1, can you be confident that no more than 2.5% of the cans of tuna have concentrations above 1 ppm mercury? Why or why not?